Autoscaling AWS Elastic Beanstalk worker tier based on SQS queue length
We are deploying a Rails application (for the Hydra-in-a-Box project) to AWS Elastic Beanstalk. Elastic Beanstalk offers us easy deployment, monitoring, and simple auto-scaling with a built-in dashboard and management interface. Our application uses several potentially long-running background jobs to characterize, checksum, and create derivates for uploaded content. Since we’re deploying this application within AWS, we’re also taking advantage of the Simple Queue Service (SQS), using the active-elastic-job gem to queue and run ActiveJob tasks.
Elastic Beanstalk provides settings for “Web server” and “Worker” tiers. Web servers are provisioned behind a load balancer and handle end-user requests, while Workers automatically handle background tasks (via SQS + active-elastic-job). Elastic Beanstalk provides basic autoscaling based on a variety of metrics collected from the underlying instances (CPU, Network, I/O, etc), although, while sufficient for our “Web server” tier, we’d like to scale our “Worker” tier based on the number of tasks waiting to be run.
Currently, though, the ability to auto-scale the worker tier based on the underlying queue depth isn’t enable through the Elastic Beanstak interface. However, as Beanstalk merely manages and aggregates other AWS resources, we have access to the underlying resources, including the autoscaling group for our environment. We should be able to attach a custom auto-scaling policy to that auto scaling group to scale based on additional alarms.
For example, let’s we want to add additional worker nodes if there are more than 10 tasks for more than 5 minutes (and, to save money and resources, also remove worker nodes when there are no tasks available). To create the new policy, we’ll need to:
- find the appropriate auto-scaling group by finding the Auto-scaling group with the
elasticbeanstalk:environment-idthat matches the worker tier environment id; - find the appropriate SQS queue for the worker tier;
- add auto-scaling policies that add (and remove) instances to the autoscaling group;
- create a new CloudWatch alarm that measures the SQS queue exceeds our configured depth (5) that triggers the auto-scaling policy to add additional worker instances whenever the alarm is triggered;
- and, conversely, create a new CloudWatch alarm that measures the SQS queue hits 09 that trigger the auto-scaling action to removes worker instances whenever the alarm is triggered.
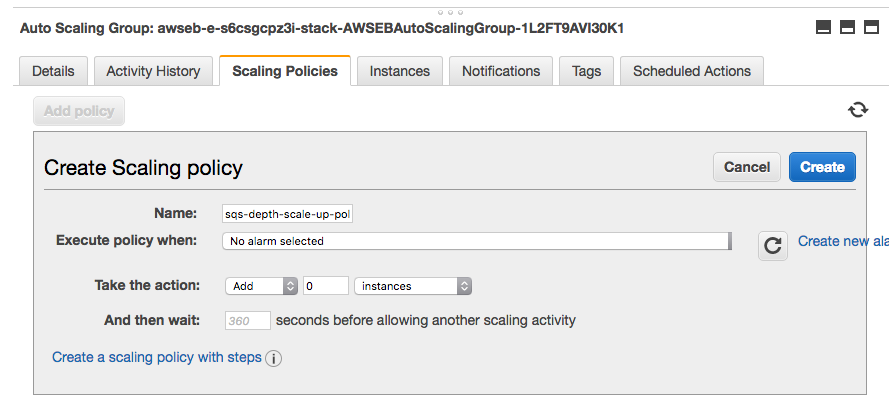
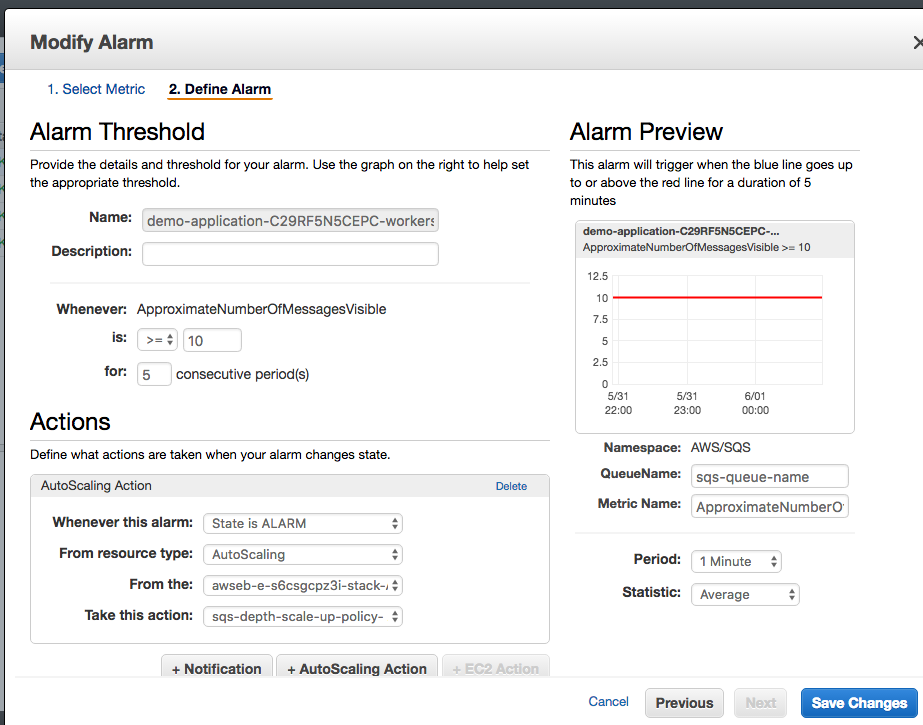
and, similarly for scaling back down. Even though there are several manual steps, they aren’t too difficult (other than discovering the various resources we’re trying to orchestrate), and using Elastic Beanstalk is still valuable for the rest of its functionality. But, we’re in the cloud, and really want to automate everything. With a little CloudFormation trickery, we can even automate creating the worker tier with the appropriate autoscaling policies.
First, knowing that the CloudFormation API allows us to pass in an existing SQS queue for the worker tier, let’s create an explicit SQS queue resource for the workers:
"DefaultQueue" : {
"Type" : "AWS::SQS::Queue",
}
And wire it up to the Beanstalk application by setting the aws:elasticbeanstalk:sqsd:WorkerQueueURL (not shown: sending the worker queue to the web server tier):
"WorkersConfigurationTemplate" : {
"Type" : "AWS::ElasticBeanstalk::ConfigurationTemplate",
"Properties" : {
"ApplicationName" : { "Ref" : "AWS::StackName" },
"OptionSettings" : [
...,
{
"Namespace": "aws:elasticbeanstalk:sqsd",
"OptionName": "WorkerQueueURL",
"Value": { "Ref" : "DefaultQueue"}
}
}
}
},
"WorkerEnvironment": {
"Type": "AWS::ElasticBeanstalk::Environment",
"Properties": {
"ApplicationName": { "Ref" : "AWS::StackName" },
"Description": "Worker Environment",
"EnvironmentName": { "Fn::Join": ["-", [{ "Ref" : "AWS::StackName"}, "workers"]] },
"TemplateName": { "Ref": "WorkersConfigurationTemplate" },
"Tier": {
"Name": "Worker",
"Type": "SQS/HTTP"
},
"SolutionStackName" : "64bit Amazon Linux 2016.03 v2.1.2 running Ruby 2.3 (Puma)"
...
}
}
Using our queue we can describe one of the CloudWatch::Alarm resources and start describing a scaling policy:
"ScaleOutAlarm" : {
"Type": "AWS::CloudWatch::Alarm",
"Properties": {
"MetricName": "ApproximateNumberOfMessagesVisible",
"Namespace": "AWS/SQS",
"Statistic": "Average",
"Period": "60",
"Threshold": "10",
"ComparisonOperator": "GreaterThanOrEqualToThreshold",
"Dimensions": [
{
"Name": "QueueName",
"Value": { "Fn::GetAtt" : ["DefaultQueue", "QueueName"] }
}
],
"EvaluationPeriods": "5",
"AlarmActions": [{ "Ref" : "ScaleOutPolicy" }]
}
},
"ScaleOutPolicy" : {
"Type": "AWS::AutoScaling::ScalingPolicy",
"Properties": {
"AdjustmentType": "ChangeInCapacity",
"AutoScalingGroupName": ????,
"ScalingAdjustment": "1",
"Cooldown": "60"
}
},
However, to connect the policy to the auto-scaling group, we need to know the name for the autoscaling group. Unfortunately, the autoscaling group is abstracted behind the Beanstalk environment.
To gain access to it, we’ll need to create a custom resource backed by a Lambda function to extract the information from the AWS APIs:
"BeanstalkStack": {
"Type": "Custom::BeanstalkStack",
"Properties": {
"ServiceToken": { "Fn::GetAtt" : ["BeanstalkStackOutputs", "Arn"] },
"EnvironmentName": { "Ref": "WorkerEnvironment" }
}
},
"BeanstalkStackOutputs": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Code": {
"ZipFile": { "Fn::Join": ["\n", [
"var response = require('cfn-response');",
"exports.handler = function(event, context) {",
" console.log('REQUEST RECEIVED:\\n', JSON.stringify(event));",
" if (event.RequestType == 'Delete') {",
" response.send(event, context, response.SUCCESS);",
" return;",
" }",
" var environmentName = event.ResourceProperties.EnvironmentName;",
" var responseData = {};",
" if (environmentName) {",
" var aws = require('aws-sdk');",
" var eb = new aws.ElasticBeanstalk();",
" eb.describeEnvironmentResources({EnvironmentName: environmentName}, function(err, data) {",
" if (err) {",
" responseData = { Error: 'describeEnvironmentResources call failed' };",
" console.log(responseData.Error + ':\\n', err);",
" response.send(event, context, resource.FAILED, responseData);",
" } else {",
" responseData = { AutoScalingGroupName: data.EnvironmentResources.AutoScalingGroups[0].Name };",
" response.send(event, context, response.SUCCESS, responseData);",
" }",
" });",
" } else {",
" responseData = {Error: 'Environment name not specified'};",
" console.log(responseData.Error);",
" response.send(event, context, response.FAILED, responseData);",
" }",
"};"
]]}
},
"Handler": "index.handler",
"Runtime": "nodejs",
"Timeout": "10",
"Role": { "Fn::GetAtt" : ["LambdaExecutionRole", "Arn"] }
}
}
With the custom resource, we can finally get access the autoscaling group name and complete the scaling policy:
"ScaleOutPolicy" : {
"Type": "AWS::AutoScaling::ScalingPolicy",
"Properties": {
"AdjustmentType": "ChangeInCapacity",
"AutoScalingGroupName": { "Fn::GetAtt": [ "BeanstalkStack", "AutoScalingGroupName" ] },
"ScalingAdjustment": "1",
"Cooldown": "60"
}
},
The complete worker tier is part of our CloudFormation stack: https://github.com/hybox/aws/blob/master/templates/worker.json