LDPath in 3 examples
At Code4Lib 2015, I gave a quick lightning talk on LDPath, a declarative domain-specific language for flatting linked data resources to a hash (e.g. for indexing to Solr).
LDPath can traverse the Linked Data Cloud as easily as working with local resources and can cache remote resources for future access. The LDPath language is also (generally) implementation independent (java, ruby) and relatively easy to implement. The language also lends itself to integration within development environments (e.g. ldpath-angular-demo-app, with context-aware autocompletion and real-time responses). For me, working with the LDPath language and implementation was the first time that linked data moved from being a good idea to being a practical solution to some problems.
Here is a selection from the VIAF record [1]:
<> void:inDataset <../data> ; a genont:InformationResource, foaf:Document ; foaf:primaryTopic <../65687612> . <../65687612> schema:alternateName "Bittman, Mark" ; schema:birthDate "1950-02-17" ; schema:familyName "Bittman" ; schema:givenName "Mark" ; schema:name "Bittman, Mark" ; schema:sameAs <http://d-nb.info/gnd/1058912836>, <http://dbpedia.org/resource/Mark_Bittman> ; a schema:Person ; rdfs:seeAlso <../182434519>, <../310263569>, <../314261350>, <../314497377>, <../314513297>, <../314718264> ; foaf:isPrimaryTopicOf <http://en.wikipedia.org/wiki/Mark_Bittman> .
We can use LDPath to extract the person’s name:

So far, this is not so different from traditional approaches. But, if we look deeper in the response, we can see other resources, including books by the author.
<../310263569>
schema:creator <../65687612> ;
schema:name "How to Cook Everything : Simple Recipes for Great Food" ;
a schema:CreativeWork .
We can traverse the links to include the titles in our record:

LDPath also gives us the ability to write this query using a reverse property selector, e.g:
books = foaf:primaryTopic / ^schema:creator[rdf:type is schema:CreativeWork] / schema:name :: xsd:string ;
The resource links out to some external resources, including a link to dbpedia. Here is a selection from record in dbpedia:
<http://dbpedia.org/resource/Mark_Bittman>
dbpedia-owl:abstract "Mark Bittman (born c. 1950) is an American food journalist, author, and columnist for The New York Times."@en, "Mark Bittman est un auteur et chroniqueur culinaire américain. Il a tenu une chronique hebdomadaire pour le The New York Times, appelée The Minimalist (« le minimaliste »), parue entre le 17 septembre 1997 et le 26 janvier 2011. Bittman continue d'écrire pour le New York Times Magazine, et participe à la section Opinion du journal. Il tient également un blog."@fr ;
dbpedia-owl:birthDate "1950+02:00"^^<http://www.w3.org/2001/XMLSchema#gYear> ;
dbpprop:name "Bittman, Mark"@en ;
dbpprop:shortDescription "American journalist, food writer"@en ;
dc:description "American journalist, food writer", "American journalist, food writer"@en ;
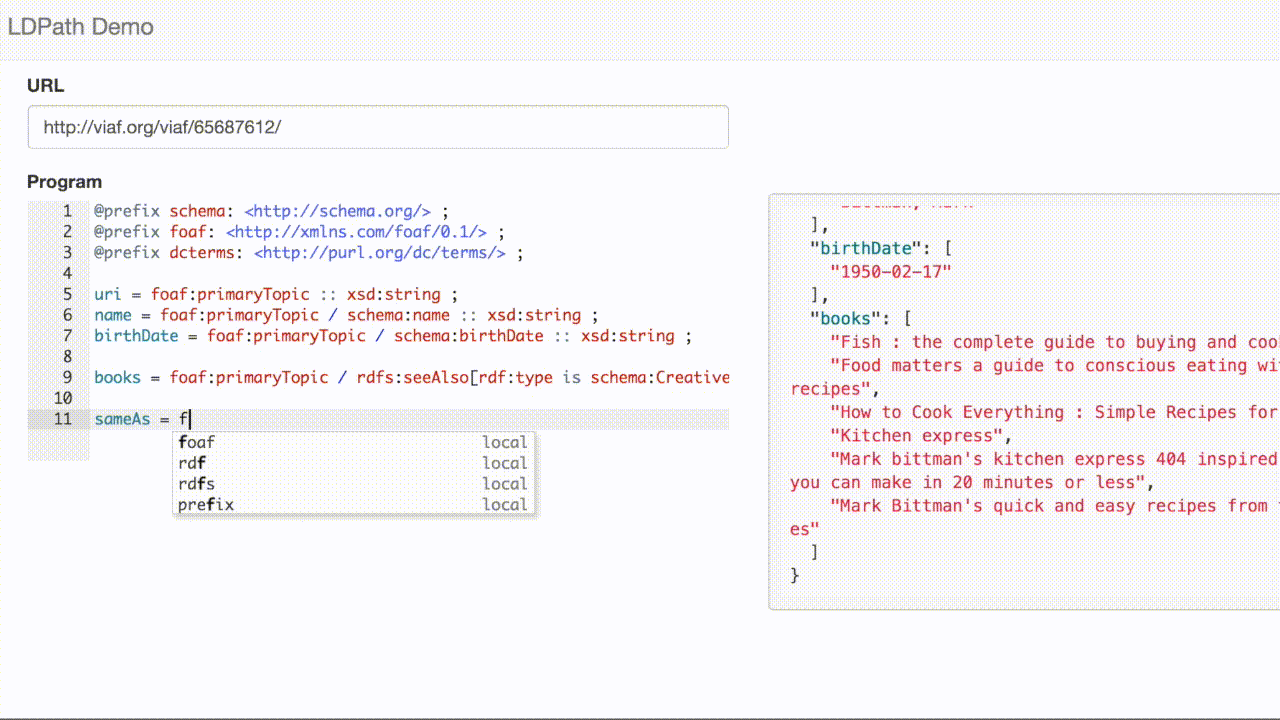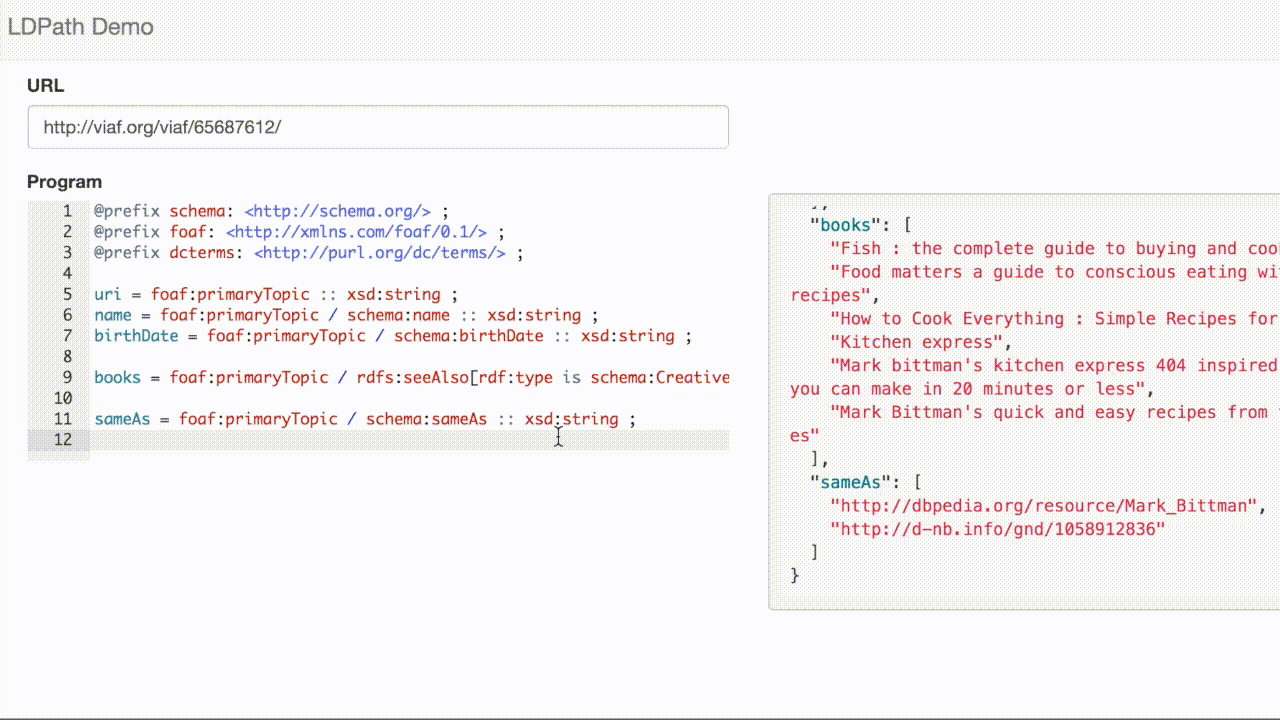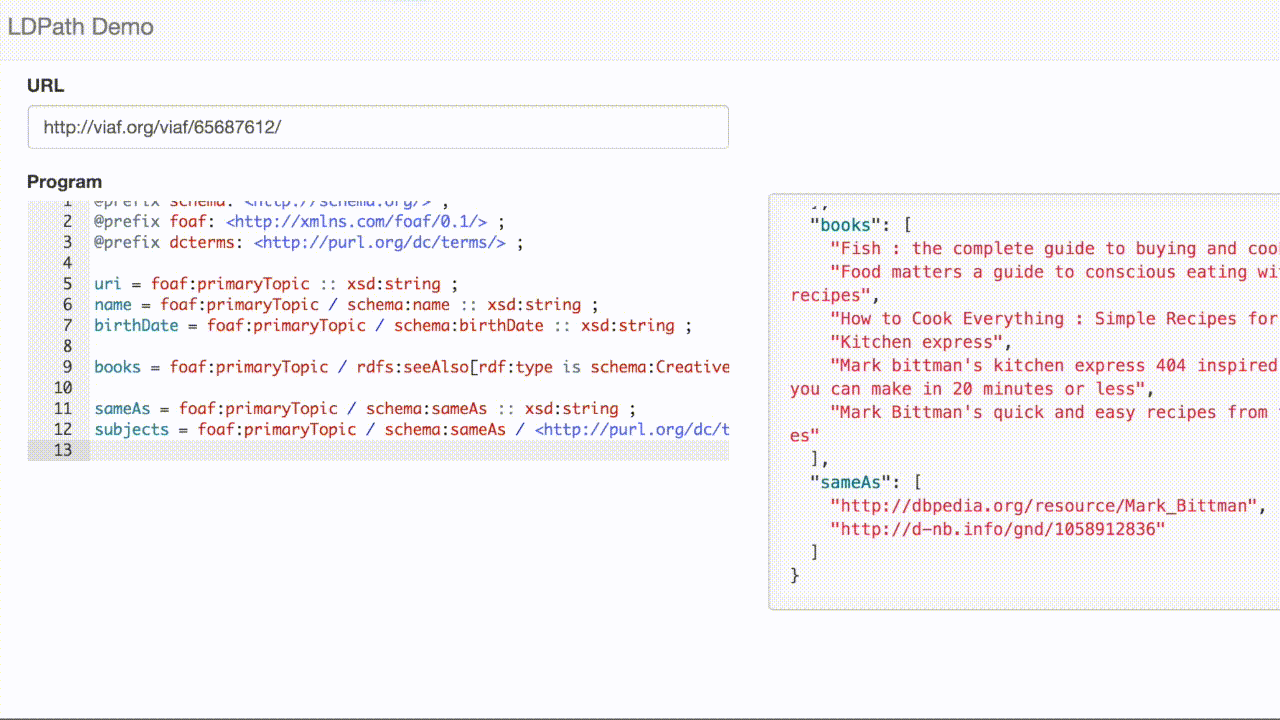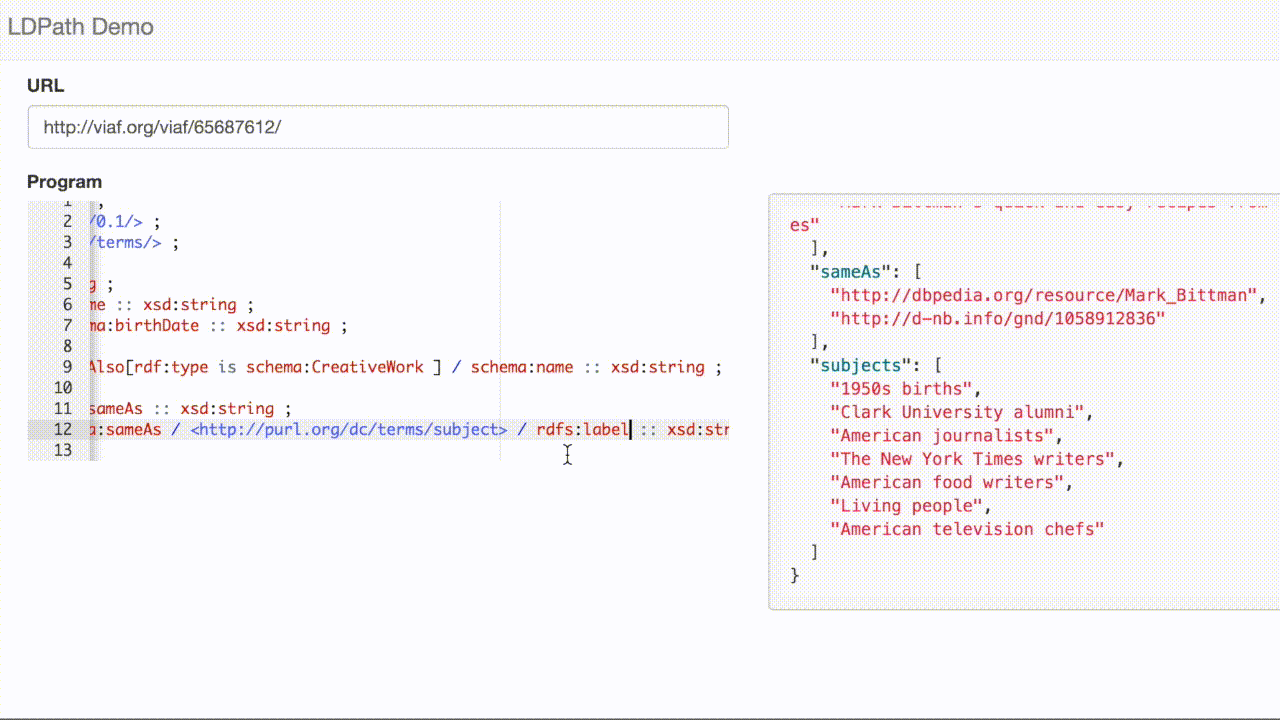
dcterms:subject <http://dbpedia.org/resource/Category:1950s_births>, <http://dbpedia.org/resource/Category:American_food_writers>, <http://dbpedia.org/resource/Category:American_journalists>, <http://dbpedia.org/resource/Category:American_television_chefs>, <http://dbpedia.org/resource/Category:Clark_University_alumni>, <http://dbpedia.org/resource/Category:Living_people>, <http://dbpedia.org/resource/Category:The_New_York_Times_writers> ;
LDPath allows us to transparently traverse that link, allowing us to extract the subjects for VIAF record:
[1] If you’re playing along at home, note that, as of this writing, VIAF.org fails to correctly implement content negotiation and returns HTML if it appears anywhere in the Accept header, e.g.:
curl -H "Accept: application/rdf+xml, text/html; q=0.1" -v http://viaf.org/viaf/152427175/
will return a text/html response. This may cause trouble for your linked data clients.